Latest from Queryloop
Stay updated with our latest research findings, product developments, and insights into AI optimization
Stay updated with our latest research findings, product developments, and insights into AI optimization
Discover how we compared 8 different parsing solutions to tackle hierarchical tables, merged cells, and horizontally tiled tables in PDFs for RAG applications.
RAG over PDFs containing complex tables has consistently posed a significant challenge. Developers experiment with various parsing solutions, but identifying the most effective parser for specific use cases remains tedious. Recently, we tackled a particularly challenging parsing scenario for one of our client's RAG use cases.
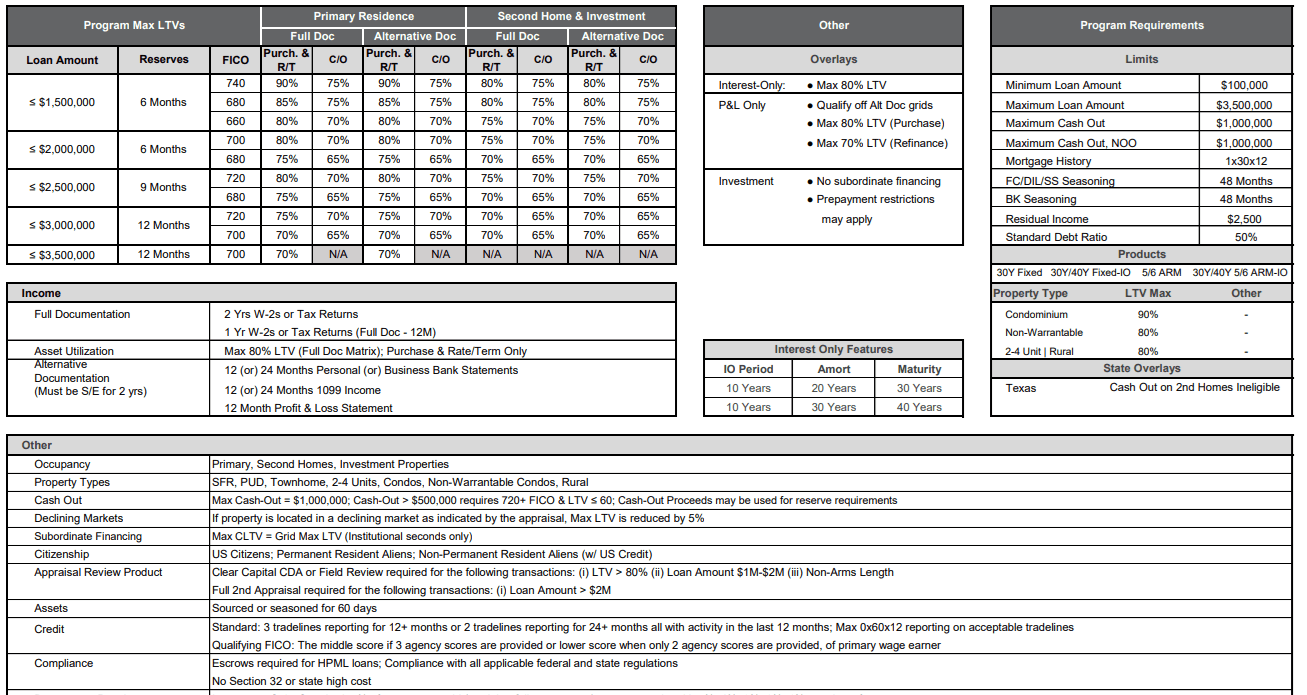
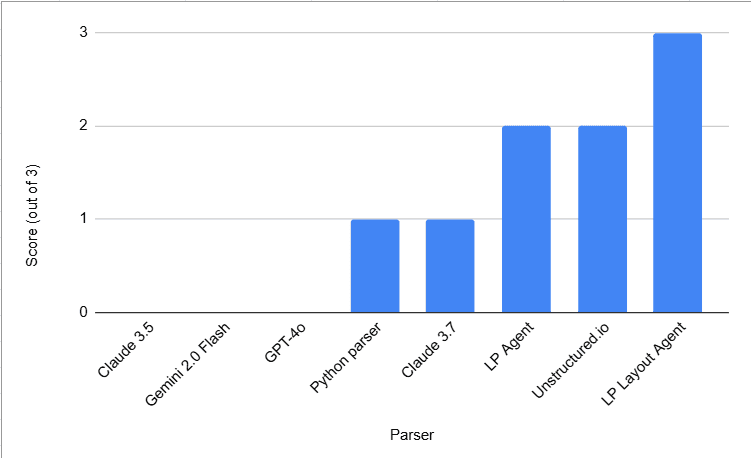
The detailed responses of Claude for each of the above parsers are given here.
Learn why creating demo RAG applications is easy, but building production-grade systems is exponentially harder, and how Queryloop solves these challenges.
Learn how Queryloop automates RAG optimization through systematic testing of parameter combinations to maximize accuracy, minimize latency, and control costs for complex document analysis.